Stable Diffusion 是一款基于深度学习的开源文本到图像生成模型,其开源性、高效性能与灵活性为 AI 绘画工具领域树立了新的标杆。该模型不仅显著降低了艺术创作的技术阈值,而且通过社区驱动的创新,在商业设计、学术研究等多个领域实现了广泛应用。
软件概述
Stable Diffusion 是由 Stability AI 与多家研究机构合作开发的一款深度学习文本到图像生成模型。该模型采用“潜在扩散模型”(Latent Diffusion Model)作为核心技术,能够依据用户提供的文本描述生成高分辨率图像,并支持图像修复、风格转换等多种复杂任务。其低硬件要求、高生成效率及开源属性使其迅速成为 AI 绘画领域的领先工具,并在艺术创作、设计辅助、教育科研以及商业内容生产等多个领域得到广泛应用。
核心功能
1. 文本到图像生成:用户输入文本描述后,模型能够生成细节丰富、风格多样的图像。
2. 图像编辑与修复:支持对现有图像进行局部重绘、去除水印、扩展画布等操作,以提升图像的可用性。
3. 风格迁移与混合:能够将一幅图像的风格迁移至另一幅图像,或融合多种艺术风格。
4. 模型微调与训练:开发者可以利用 LoRA 等技术,基于少量数据对模型进行定制化训练,以满足特定领域的需求。
软件特点
1. 开源与社区生态:遵循 Apache 2.0 协议开源,支持商业用途,社区提供了大量预训练模型、插件及教程,降低了使用难度。
2. 轻量级部署:经过优化的模型可在消费级 GPU 上运行,使得个人电脑即可实现高质量图像的生成。
3. 多模态扩展性:支持与 ControlNet 等插件结合使用,通过边缘检测、深度图等条件控制生成内容,提高生成精准度。
4. 跨平台兼容性:提供 Windows、macOS、Linux 版本,并集成至 Hugging Face、Google Colab 等平台,便于云端调用。
操作指南
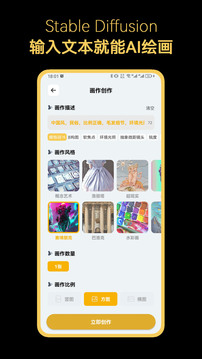
1. 下载安装并启动 Stable Diffusion,点击界面下方的“+”按钮。
2. 点击“随机输入”选项。
3. 选择“免费创作”模式。
4. 按照界面提示操作,点击“继续创作”按钮即可返回上一页面进行文本内容的更换。
版本更新
v5.3:
兼容部分 Android 12+ 机型手机;
优化 AI 绘画生成效率;
修复已知问题。